Scene categorization is a fundamental problem in computer vision. However, scene understanding research has been constrained by the limited scope of currently-used databases which do not capture the full variety of scene categories. Whereas standard databases for object categorization contain hundreds of different classes of objects, the largest available dataset of scene categories contains only 15 classes. In this paper we propose the extensive Scene UNderstanding (SUN) database that contains 899 categories and 130,519 images. We use 397 well-sampled categories to evaluate numerous state-of-the-art algorithms for scene recognition and establish new bounds of performance. We measure human scene classification performance on the SUN database and compare this with computational methods.
J. Xiao, J. Hays, K. Ehinger, A. Oliva, and A. Torralba.
SUN Database: Large-scale Scene Recognition from Abbey to Zoo.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
J. Xiao, K. A. Ehinger, J. Hays, A. Torralba, and A. Oliva.
SUN Database: Exploring a Large Collection of Scene Categories
International Journal of Computer Vision (IJCV)
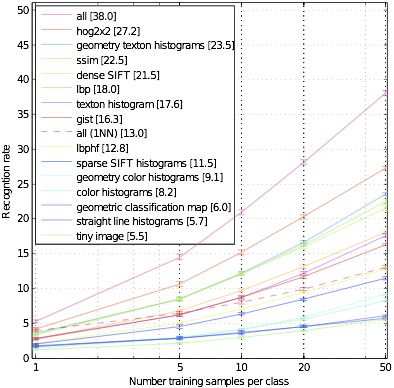
We use 397 well-sampled categories to evaluate numerous state-of-the-art algorithms for scene recognition and establish new bounds of performance. The results are shown in the figure on the right.
We visualize the results using the combined kernel from all features for the first training and testing partition in the following webpage. For each of the 397 categories, we show the class name, the ROC curve, 5 sample traning images, 5 sample correct predictions, 5 most confident false positives (with true label), and 5 least confident false negatives (with wrong predicted label).
The database contains 397 categories SUN dataset used in the benchmark of the paper. The number of images varies across categories, but there are at least 100 images per category, and 108,754 images in total. Images are in jpg, png, or gif format. The images provided here are for research purposes only.
For the results in the paper we use a subset of the dataset that has 50 training images and 50 testing images per class, averaging over the 10 partitions in the following. To plot the curve in Figure 4(b) of the paper, we use the first n=(1, 5, 10, 20) images outof the 50 training images per class for training, and use all the same 50 testing images for testing no matter what size the training set is. (If you are using Microsoft Windows, you may need to replace / by \ in the following files.)
We have manually built an overcomplete three-level hierarchy for all 908 scene categories. The scene categories are arranged in a 3-level tree: with 908 leaf nodes (SUN categories) connected to 15 parent nodes at the second level (basic-level categories) that are in turn connected to 3 nodes at the first level (superordinate categories) with the root node at the top. The hierarchy is not a tree, but a Directed Acyclic Graph. Many categories such as "hayfield" are duplicated in the hierarchy because there might be confusion over whether such a category belongs in the natural or man-made sub-hierarchies.
The feature matrices are avialble at THIS LINK.
DrawMe is a light-weight Javascript library to enable client-end line drawing on a picture in a web browser. It is targeted to provide a basis for self-define labeling tasks for computer vision researchers. It is different from LabelMe, which provides full support but fixed labeling interface. DrawMe is a Javascript library only and the users are required to write their own code to make use of this library for their specific need of labeling. DrawMe does not provide any server or server-end code for labeling, but gives the user greater flexibility for their specific need. It also comes with a simple example with Amazon Mechanical Turk interface that serializes Javascript DOM object into text for HTML form submission. The user can easily build their own labeling interface based on this MTurk example to make use for the Amazon Mechanical Turk for labeling, either using paid workers or the researchers themselves with MTurk sandbox.
This work is funded by NSF CAREER Awards 0546262 to A.O, 0747120 to A.T. and partly funded by BAE Systems under Subcontract No. 073692 (Prime Contract No. HR0011-08-C-0134 issued by DARPA), Foxconn and gifts from Google and Microsoft. K.A.E is funded by a NSF Graduate Research fellowship.